Pandas in action. #GroupBy
Uno de los métodos que más utilizo a la hora de realizar un análisis exploratorio de los datos, es la utilización de la función Group by de la librería de Pandas.
De acuerdo a la documentación oficial de Pandas, estos son los parámetros que
recibe como argumento.
pandas.DataFrame.groupby
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
# https://pandas.pydata.org/docs/reference/groupby.html
|
|
Importamos nuestro dataset.
import pandas as pd
df = pd.read_csv('titanic.csv', delimiter=',')
Veamos algunas de las funcionalidades que nos ofrece groupBy.
La primera es agrupar el dataframe por uno de los campos que nos interesa, en este caso vamos a seleccionar el campo "Pclass" para que nos de información al respecto.
La primer función que vamos a utilizar es count() para que nos muestre el resultado agrupado contando de acuerdo a las Clases (Pclass).
Si sabemos que el campo PassengerId es único, podemos determinar la cantidad
de pasajeros de cada clase.
df_grp = df.groupby("Pclass").count()
df_grp
# otra forma es la siguiente
df_grp = df.groupby("Pclass")
df_grp.count()
Obteniendo información de los grupos
Para obtener información de los grupos solo ejecutamos la linea con el argumento
con lo cual queremos agrupar, luego podemos invocar los distintos metodos para
obtener información de los grupos, como ngroups que nos da la cantidad de grupos, etc
df_grp = df.groupby("Pclass")
df_grp
print("Cantidad de grupos ..",df_grp.ngroups) # amount of groups ..
print("Tamaño de los grupos")
#df_grp.size() # compute group sizes ... ;)
print(df_grp.size())
# group retorna las rows de cada grupo.
# {1: [1, 3, 6, 11, 23 .....
print(df_grp.groups)
Los métodos First() y Last() muestran los primeros y últimos elementos.
display(df_grp.first())
display(df_grp.last())
En caso de que necesitamos analizar o ver los datos de un grupo en especifico, podemos utilizar lo siguiente:
df_grp_1 = df_grp.get_group(1)
df_grp_1.head()
Utilizamos el metodo get_group() pasandole como argumento el grupo, en este caso la Clase 1.
Agrupando por multiples columnas.
Para agrupar mas de una columna, basta con solo concatenar las columnas con el argumento by=["col1", "col2"]; en este caso se agregó el argumento dropna que por defecto es igual a True, el cual ignora los resultados vacios, en este caso lo seteamos a False para ver los resultados con ambos valores.
# Agrupar por multiples columnas el argumento dropna=False ignora las filas nan
df.groupby(by=["Sex", "Pclass"], dropna=False).count()
Utilizando múltiples funciones; para esta utilizaremos el método agg(). Veamos un ejemplo de como utilizarlo.
DataFrame.agg(func=None, axis=0, *args, **kwargs)
df.groupby(by=["Sex", "Pclass"]).Age.agg(['max', 'min', 'count', 'median', 'mean'])
Agrupamos por Sex + PClass y aesto le aplicamos las funciones de Max, min, Count, Median y Mean.
De esta manera la salida nos da muchísma información, como la edad, como la edad maxima, minima de cada sexo y clase, además de la mediana y promedio
Otra alternativa para agrupar con multiples funciones, puede ser la siguiente, crear otro df, con los datos que nos interesan y agruparlos, para asi poder trabajar con los datos que nos interesan y además tener una mejor visualización de los datos.
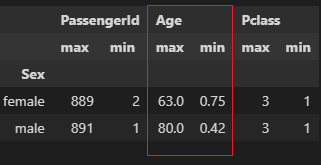
df_1 = df[["PassengerId", "Age", "Pclass", "Sex"]]
df_1.groupby('Sex').agg(['max', 'min'])
Otra alternativa para utilizar funciones con el método agg() es la de crear nuestras propias funciones.
Conclusión
GroupBy es un gran aliado a la hora de analizar datos por parte de un Analista de Datos; conocer la mayoria de funcionalidades es crucial para poder lograr nuestros objetivos a la hora de realizar un análisis exploratorio de los datos.
https://github.com/miguelsquillari/dataScience
References:
https://pandas.pydata.org/pandas-docs/stable/user_guide/groupby.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.agg.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.groupby.html





Comentarios
Publicar un comentario